AI API cost spikes don't behave like traditional system failures. There's no crash, no alert storm, no pager notification in the middle of the night. Everything keeps working. Requests succeed. Users stay happy. And yet, quietly, costs start climbing.
This is exactly why most teams catch AI cost issues too late.
Silent Failures in AI Systems
In traditional infrastructure, problems announce themselves loudly. A database slows down. A service times out. Error rates spike. Engineers respond because something is visibly broken. AI cost overruns don't follow this pattern. They are silent failures.
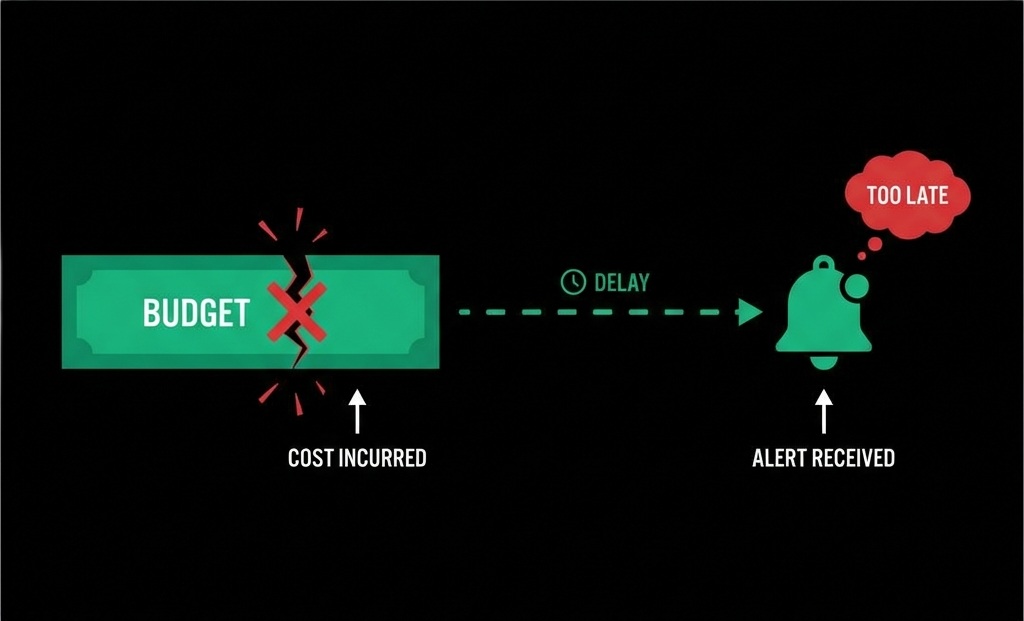
The core issue is timing. Most teams rely on provider dashboards to understand usage. These dashboards are fundamentally retrospective. They tell you what already happened, not what is about to happen. By the time you see a cost spike, the money is already gone.
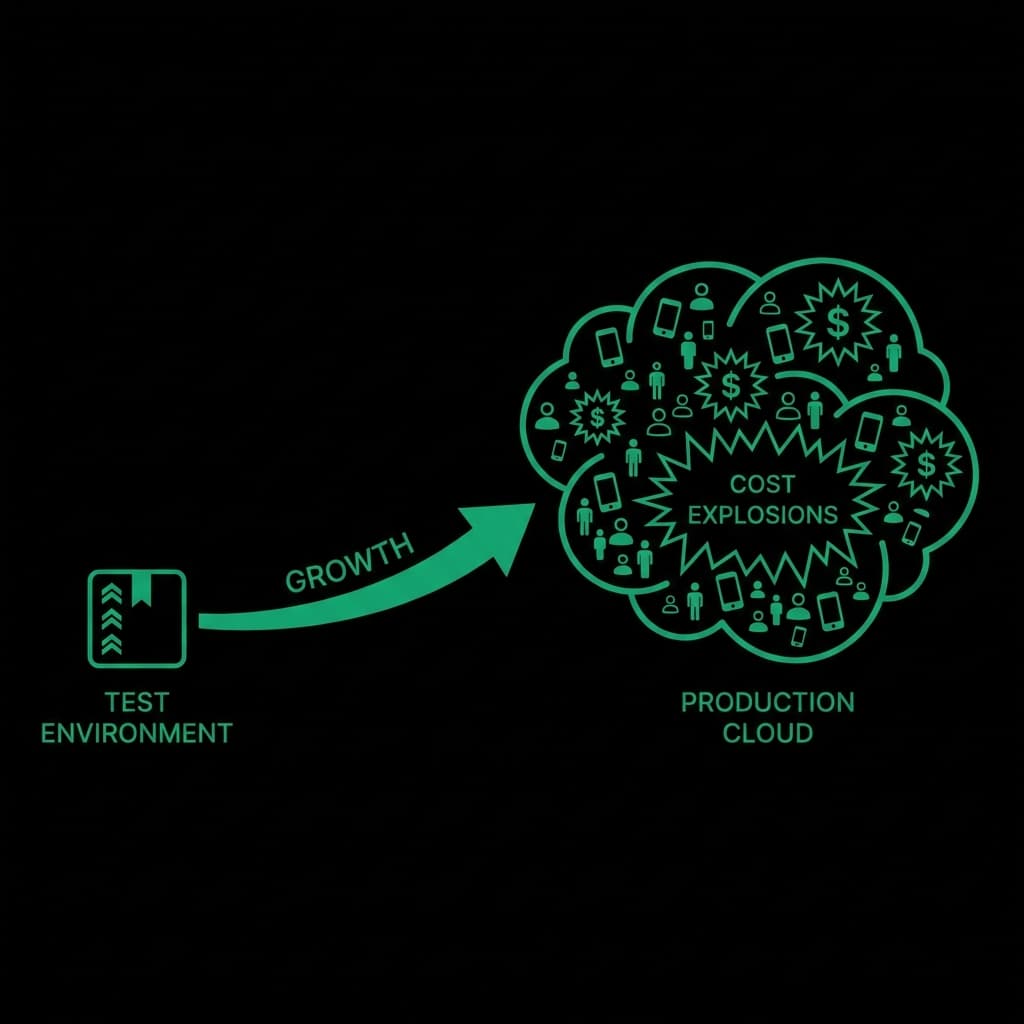
When Development Meets Production
Early in development, this doesn't matter much. Traffic is low. Prompts are small. Usage is predictable. But once a system reaches production, inputs stop being controlled. Real users behave differently than test data. They paste large documents. They retry actions repeatedly. They trigger flows you didn't anticipate.
Cost spikes almost always come from "valid" behavior:
- A retry loop that technically works
- A prompt that grows with user input
- A background job that scales faster than expected
- A feature launch that suddenly multiplies traffic
None of these are bugs in the traditional sense. The system is doing exactly what it was designed to do. That's what makes detection so difficult.
Why Traditional Monitoring Fails
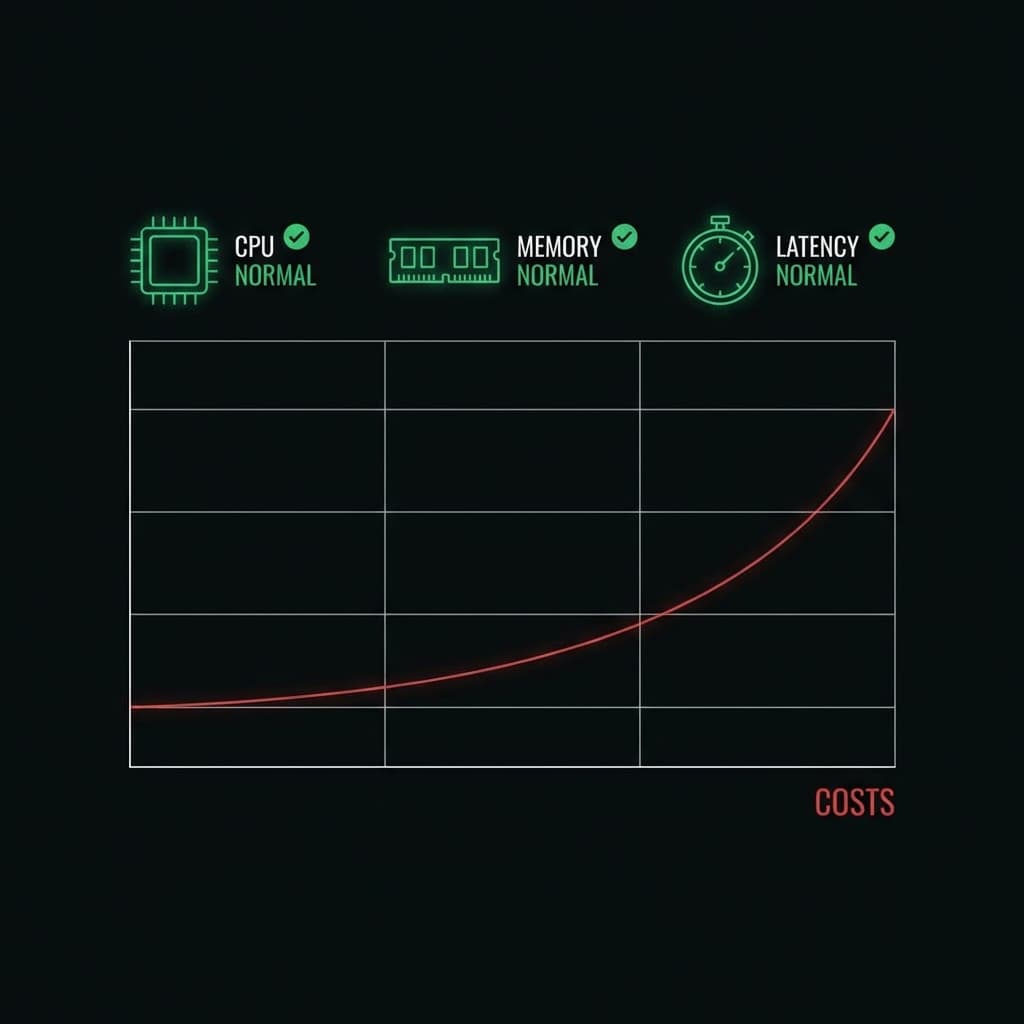
Monitoring tools don't help much here. Latency looks normal. Error rates are low. CPU and memory are stable. From an SRE perspective, the system is healthy. From a financial perspective, it's bleeding.
The uncomfortable truth is that cost needs to be treated as a runtime signal, not a billing artifact. If cost is only visible after execution, you've already lost control.
Shifting Enforcement Earlier
Teams that successfully avoid cost spikes shift enforcement earlier. They evaluate requests before execution. They ask questions like:
- How large is this request?
- How often is this endpoint being hit?
- Is this request within expected cost boundaries?
When cost becomes part of request validation, spikes stop being surprises. They become blocked events.
This isn't about being restrictive. It's about restoring predictability. Engineers should be able to ship features without wondering whether the next deploy will double their bill.