AI APIs don't fail because they are expensive. They fail because cost is evaluated after execution.
Once a request is processed, tokens are consumed and the cost is irreversible. Dashboards and alerts only explain what already happened.
This article explains why unexpected AI API bills occur and how they can be prevented before any money is spent.
Why AI API Bills Suddenly Spike
Unexpected costs usually come from normal system behavior, not bugs.
Common causes:
- Large user inputs (documents, logs, raw text)
- Retry loops after transient failures
- Background jobs without usage caps
- Model changes with higher token pricing
- Abuse or malformed requests
These events are hard to predict but easy to prevent if cost is evaluated early.
Why Alerts Are Too Late
Usage alerts trigger after the request completes.
By the time an alert fires:
- The provider already billed the request
- The budget is already affected
- There is nothing left to stop
Alerts create visibility, not protection.
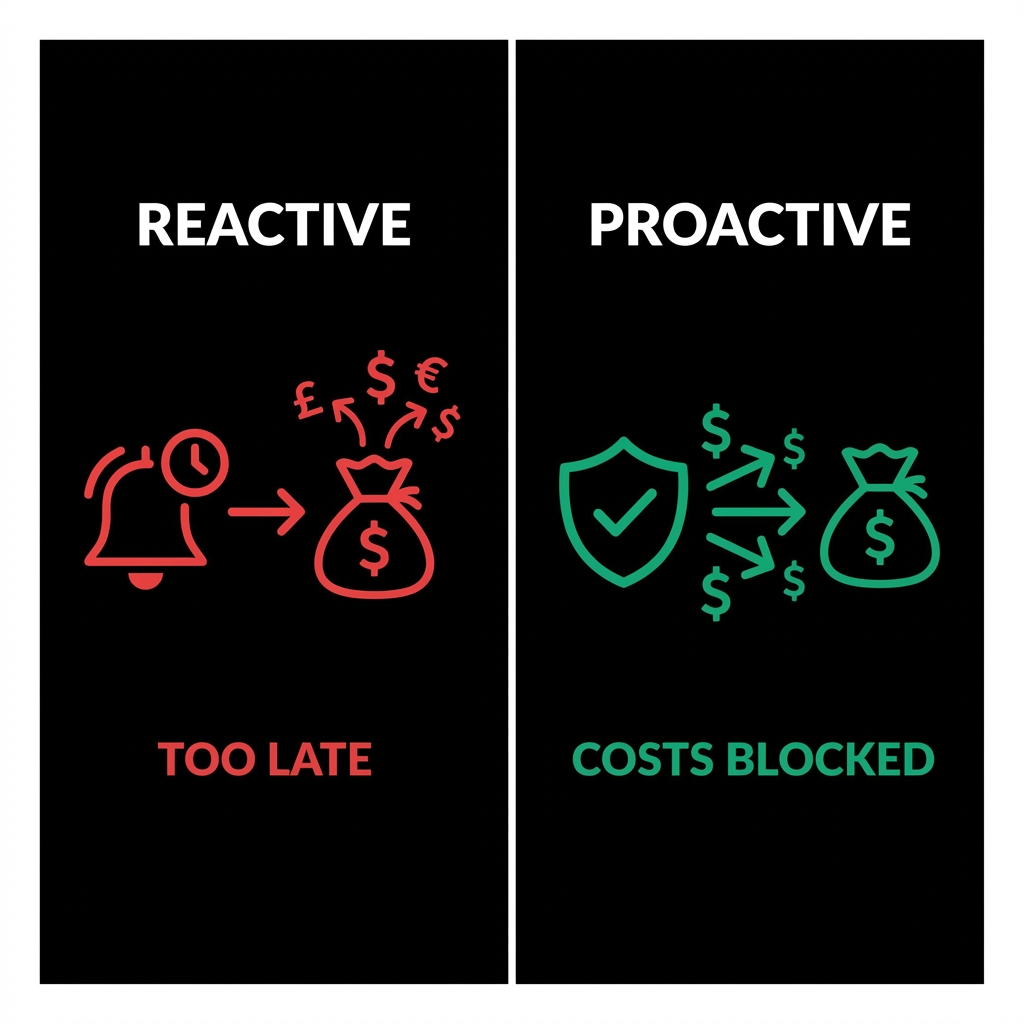
What Pre-flight Cost Checking Actually Does
Pre-flight cost checking evaluates a request before it reaches the AI provider.
The system:
- Estimates token usage
- Calculates worst-case cost
- Compares it against defined policies
- Allows or blocks the request
If blocked, the provider is never called.
Blocking a Request Is a Safety Feature
Blocking is not a failure state. It is a controlled financial decision.
Typical rules:
- Max cost per request
- Daily or monthly project budgets
- User-level or environment-level limits
Blocking prevents cost escalation without breaking the system.
Real Example
A user uploads a large PDF.
Without protection:
- Entire file sent to LLM
- Cost spikes dramatically
- Alert arrives too late
With pre-flight checks:
- Estimated cost exceeds limit
- Request is blocked
- No tokens consumed
- No unexpected bill
Conclusion
Unexpected AI API bills are not an accounting problem. They are a request-time control problem.
If cost is not evaluated before execution, it cannot be controlled.