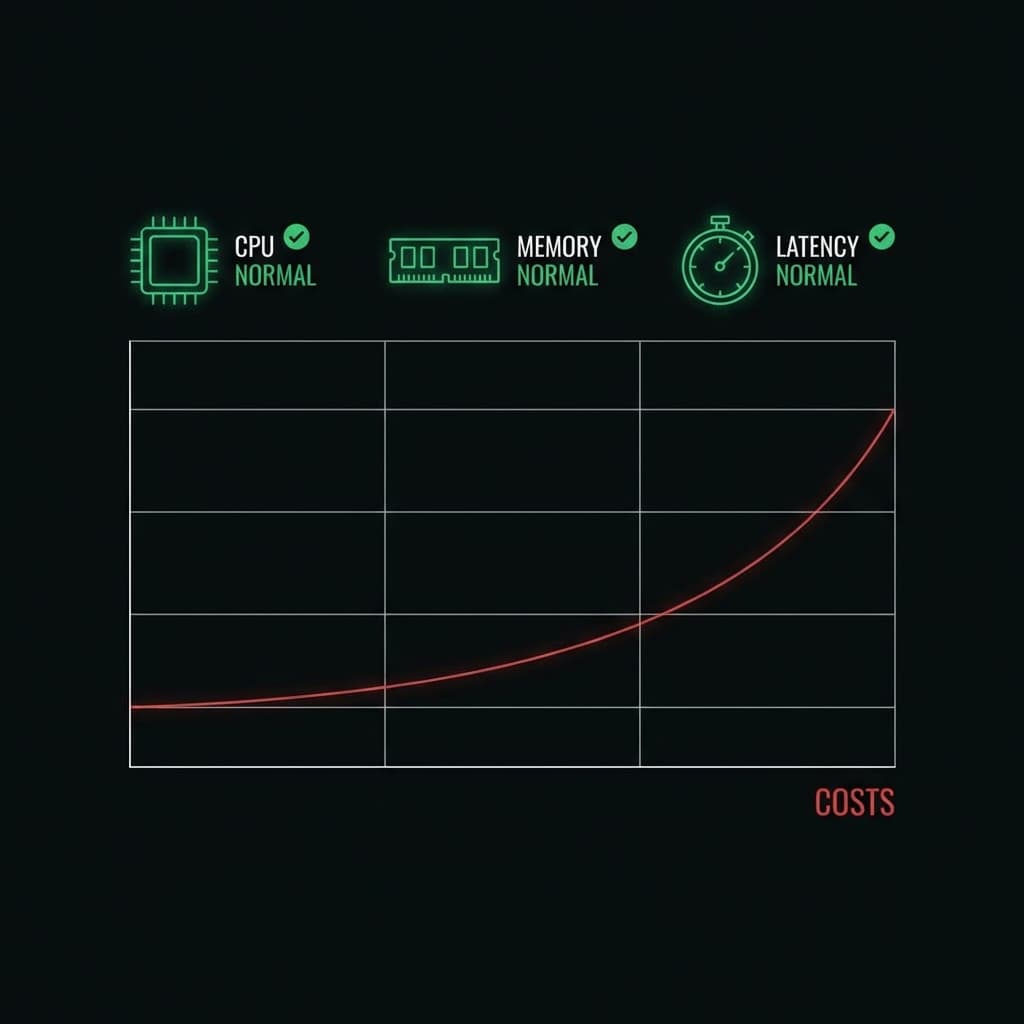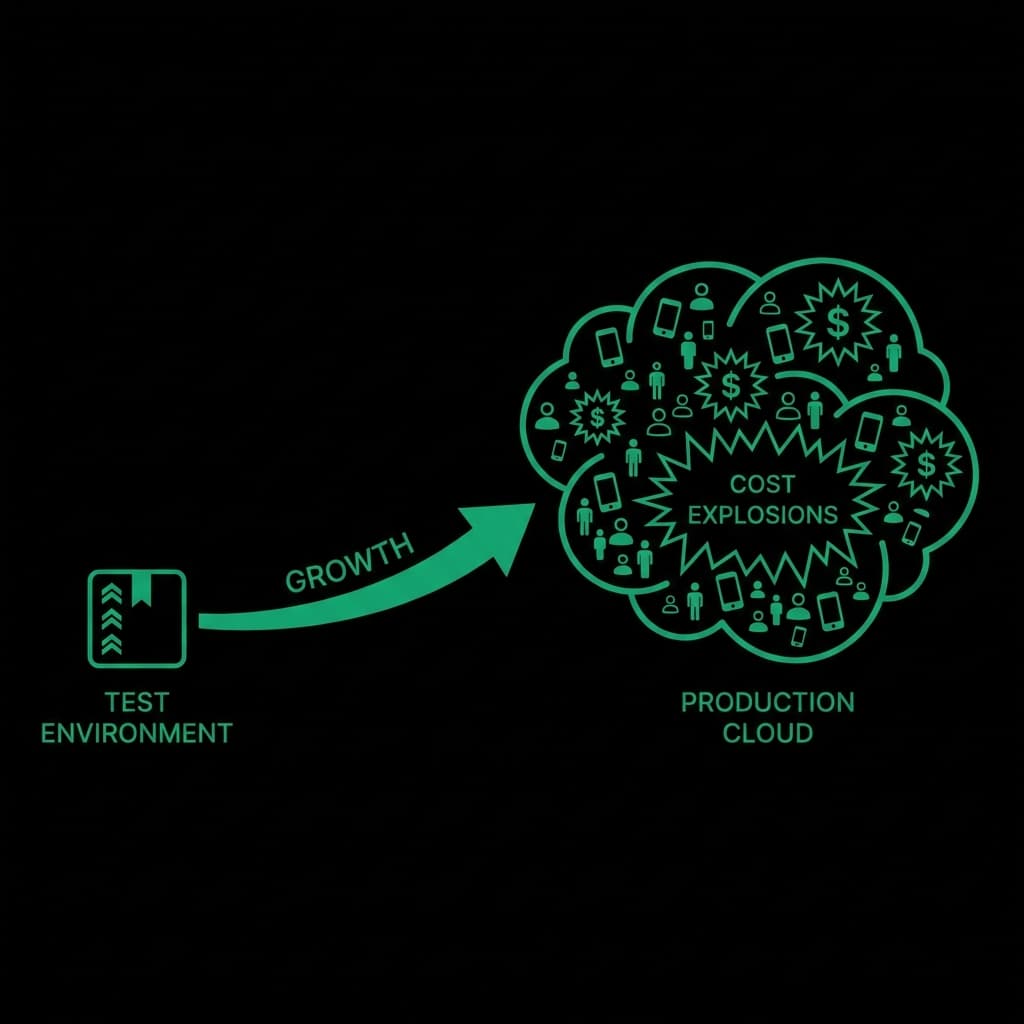
Once an LLM request executes, cost is final.
Pre-flight checks exist to answer one question: Is this request safe to execute?
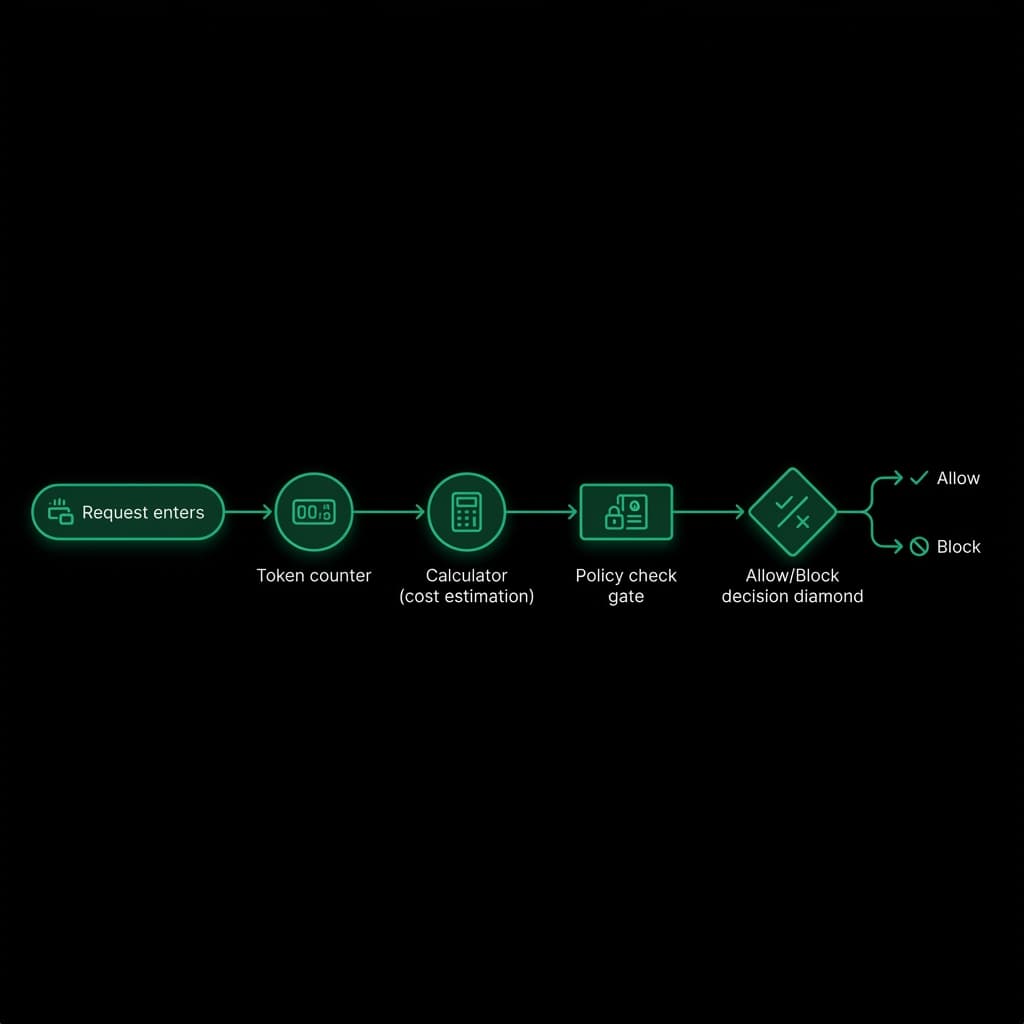
What Happens During a Pre-flight Check
Before execution:
- Request metadata is extracted
- Token usage is estimated
- Worst-case cost is calculated
- Policies are evaluated
- A decision is made
Only approved requests reach the provider.
Token Estimation Is About Safety, Not Precision
Exact token counts are not required.
Effective systems:
- Use conservative estimates
- Assume maximum output
- Apply buffers
The goal is preventing risk, not perfect accuracy.
Why Post-flight Tracking Is Insufficient
Post-flight tracking:
- Confirms what happened
- Helps reporting
- Cannot undo cost
Control must happen before execution.
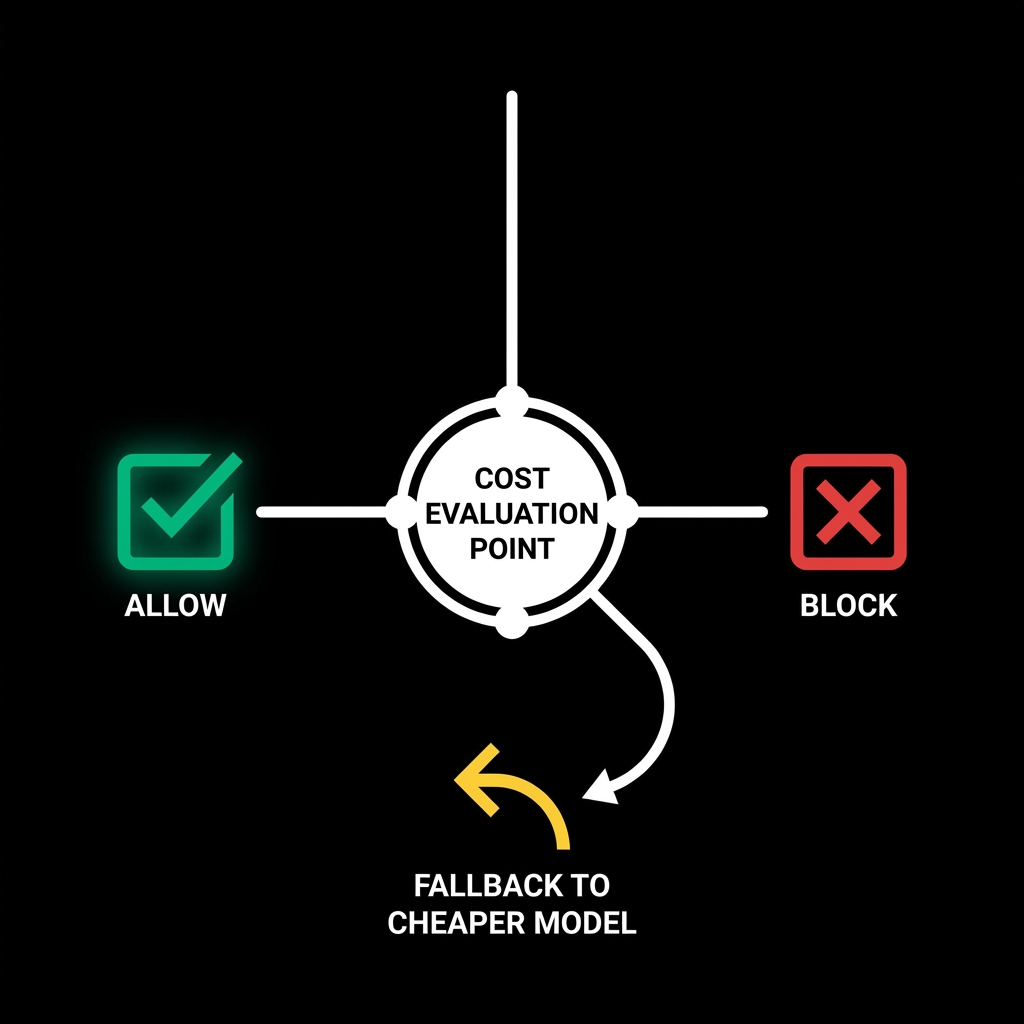
Allow, Block, or Fallback
Decisions include:
- Allow: request proceeds
- Block: request rejected
- Optional fallback: route to cheaper model
Decisions must be fast and deterministic.
Reliability Considerations
A cost control system must:
- Never break production traffic
- Fail open if unavailable
- Add minimal latency
Cost safety must not reduce system reliability.
Conclusion
Pre-flight cost checks are not optional in production AI systems.
They are the only way to enforce budget safety.